Getting Started with Solr
Hi Friends my first post will be, Installing the Solr and how to index the Sample File Given in the Examples.
Step:1
Download the Apache Solr Latest Version , I downloaded the Version 6.4.2
Step:2
Before Starting the Apache Solr make sure that you have the Java 1.8 or Higher Version.
Step:3
Start the Server using the Command solr.cmd start
once if the server is started then you can access by the url
http://localhost:8983/solr/#
once you start the server then you will get the below console
Step:4
In Solr the term core is used to refer to a single index,
So before staring the search create the Core by the following way.

once you start the server then you will get the below console

Step:4
In Solr the term core is used to refer to a single index,
So before staring the search create the Core by the following way.
Navigate to the solr-6.2.0\bin folder in command prompt
And run the below command
solr create –c refrence

Step:5
Once the Server is started you have index the Examples by the below Method
<Solr-ExtractedPath>/
And Execute java -Dc=refrence -Dauto -jar example\exampledocs\post.jar -c .\docs
Once if you execute the above script it will index the files inside the docs.
Challenges :
bin/post exists currently only as a Unix shell script, however it delegates its work to a cross-platform capable Java program. The SimplePostTool can be run directly in supported environments, including Windows. By the above Script.
Once you execute the above link
SimplePostTool can be used to index .
Errors:
Execute the post command Directly you will get the below error.
'post' is not recognized as an internal or external command,
operable program or batch file.
So use the steps I have given to resolve
SimplePostTool version 5.0.0
Posting files to [base] url http://localhost:8983/solr/gettingstarted/update using content-type application/xml...
SimplePostTool: WARNING: No files or directories matching -c
SimplePostTool: WARNING: No files or directories matching refrence
POSTing file films.json to [base]
SimplePostTool: WARNING: Solr returned an error #404 (Not Found) for url: http://localhost:8983/solr/gettingstarted/update
SimplePostTool: WARNING: Response: <html>
<head>
<meta http-equiv="Content-Type" content="text/html;charset=utf-8"/>
<title>Error 404 Not Found</title>
</head>
<body><h2>HTTP ERROR 404</h2>
<p>Problem accessing /solr/gettingstarted/update. Reason:
<pre> Not Found</pre></p>
</body>
</html>
SimplePostTool: WARNING: IOException while reading response: java.io.FileNotFoundException: http://localhost:8983/solr/gettingstarted/update
1 files indexed.
COMMITting Solr index changes to http://localhost:8983/solr/gettingstarted/update...
SimplePostTool: WARNING: Solr returned an error #404 (Not Found) for url: http://localhost:8983/solr/gettingstarted/update?commit=true
SimplePostTool: WARNING: Response: <html>
<head>
<meta http-equiv="Content-Type" content="text/html;charset=utf-8"/>
<title>Error 404 Not Found</title>
</head>
<body><h2>HTTP ERROR 404</h2>
<p>Problem accessing /solr/gettingstarted/update. Reason:
<pre> Not Found</pre></p>
</body>
</html>
Time spent: 0:00:00.589
if the above error comes make sure that you are passing the Correct arguments .
java -Dc=refrence -Dauto -jar example\exampledocs\post.jar -c example\exampledocs
Once if you do this it will index the Files as below
SimplePostTool version 5.0.0
Posting files to [base] url http://localhost:8983/solr/refrence/update...
Entering auto mode. File endings considered are xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx,odt,odp,ods,ott,otp,ots,rtf,htm,html,txt,log
SimplePostTool: WARNING: No files or directories matching -c
Indexing directory example\exampledocs (19 files, depth=0)
POSTing file books.csv (text/csv) to [base]
POSTing file books.json (application/json) to [base]/json/docs
POSTing file gb18030-example.xml (application/xml) to [base]
POSTing file hd.xml (application/xml) to [base]
POSTing file ipod_other.xml (application/xml) to [base]
POSTing file ipod_video.xml (application/xml) to [base]
POSTing file manufacturers.xml (application/xml) to [base]
POSTing file mem.xml (application/xml) to [base]
POSTing file money.xml (application/xml) to [base]
POSTing file monitor.xml (application/xml) to [base]
POSTing file monitor2.xml (application/xml) to [base]
POSTing file more_books.jsonl (application/json) to [base]/json/docs
POSTing file mp500.xml (application/xml) to [base]
POSTing file sample.html (text/html) to [base]/extract
POSTing file sd500.xml (application/xml) to [base]
POSTing file solr-word.pdf (application/pdf) to [base]/extract
POSTing file solr.xml (application/xml) to [base]
POSTing file utf8-example.xml (application/xml) to [base]
POSTing file vidcard.xml (application/xml) to [base]
19 files indexed.
COMMITting Solr index changes to http://localhost:8983/solr/refrence/update...
Time spent: 0:00:12.995
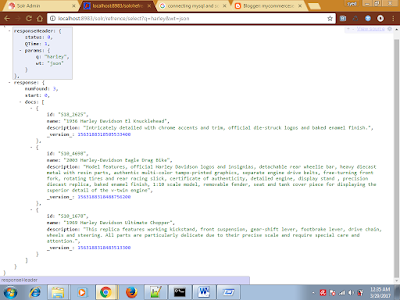
Once Indexing is done then you can access by the Followin url or search by the following url
Access: